Dubleeritud andmed võivad sageli põhjustada segadust, vigu ja moonutatud arusaamu. Õnneks pakub Google'i arvutustabelid meile palju tööriistu ja tehnikaid nende üleliigsete kirjete tuvastamise ja eemaldamise lihtsustamiseks. Alates põhilistest lahtrite võrdlustest kuni täiustatud valemipõhiste lähenemisviisideni saate muuta segased lehed organiseeritud väärtuslikeks ressurssideks.
Olenemata sellest, kas käsitlete klientide loendeid, küsitlustulemusi või muid andmekogumeid, on topeltkirjete kõrvaldamine oluline samm usaldusväärse analüüsi ja otsuste tegemise suunas.
Selles juhendis käsitleme kahte meetodit, mis võimaldavad teil dubleerivaid väärtusi tuvastada ja eemaldada.
Tabeli loomine
Esmalt lõime Google'i arvutustabelites tabeli, mida kasutatakse käesoleva artikli näidetes. Selles tabelis on 3 veergu: veerg A päisega “Nimi” salvestab nimed; Veerus B on päis “Vanus”, mis sisaldab inimeste vanuseid; ja lõpuks, veerg C, päis 'Linn', sisaldab linnu. Kui me jälgime, siis mõned selle tabeli kirjed on dubleeritud, näiteks kirjed 'John' ja 'Sara'.
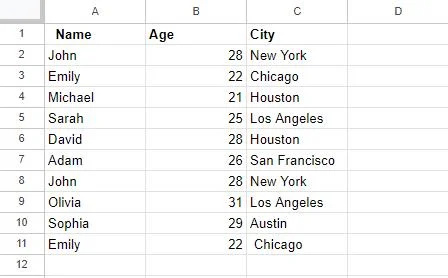
Töötame selle tabeli kallal, et eemaldada need dubleerivad väärtused erinevate meetoditega.
1. meetod: Google'i arvutustabelite funktsiooni „Duplikaatide eemaldamine” kasutamine
Esimene meetod, mida siin käsitleme, on duplikaatväärtuste eemaldamine, kasutades Google'i lehe funktsiooni „Duplikaatide eemaldamine”. See meetod kõrvaldab valitud lahtrivahemikust dubleeritud kirjed jäädavalt.
Selle meetodi demonstreerimiseks vaatleme uuesti ülaltoodud tabelit.
Selle meetodi kallal töötamise alustamiseks peame kõigepealt valima kogu meie andmeid sisaldava vahemiku, sealhulgas päised. Selle stsenaariumi korral oleme valinud lahtrid A1:C11 .
Google'i arvutustabelite akna ülaosas näete erinevate menüüdega navigeerimisriba. Otsige üles ja klõpsake navigeerimisribal suvand 'Andmed'.
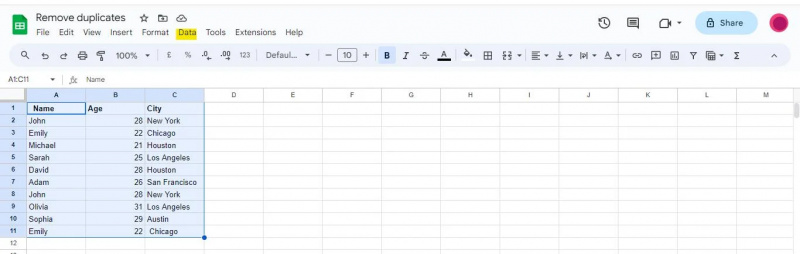
Kui klõpsate valikul Andmed, kuvatakse rippmenüü, mis pakub teile erinevaid andmetega seotud tööriistu ja funktsioone, mida saab kasutada andmete analüüsimiseks, puhastamiseks ja töötlemiseks.
Selle näite puhul peame avama menüü „Andmed”, et liikuda suvandile „Andmete puhastamine”, mis sisaldab funktsiooni „Duplikaatide eemaldamine”.
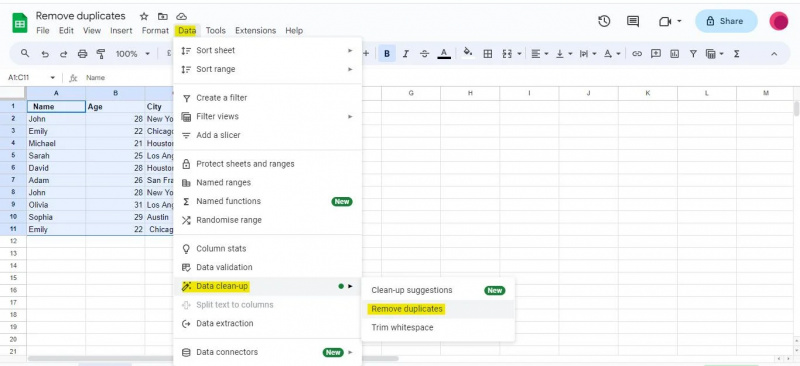
Pärast dialoogiboksi „Duplikaatide eemaldamine” avamist kuvatakse meile meie andmestiku veergude loend. Nende veergude põhjal leitakse ja eemaldatakse duplikaadid. Märgistame dialoogiboksis vastavad märkeruudud sõltuvalt sellest, milliseid veerge soovime duplikaatide tuvastamiseks kasutada.
Meie näites on kolm veergu: 'Nimi', 'Vanus' ja 'Linn'. Kuna soovime tuvastada duplikaate kõigi kolme veeru põhjal, oleme märkinud kõik kolm märkeruutu. Peale selle peate märkima märkeruudu 'Andmed sisaldavad päise rida', kui teie tabelis on päised. Kuna ülaltoodud tabelis on päised, oleme märkinud märkeruudu „Andmed sisaldavad päise rida”.
Kui oleme duplikaatide tuvastamiseks veerud valinud, saame jätkata nende duplikaatide eemaldamist oma andmekogumist.
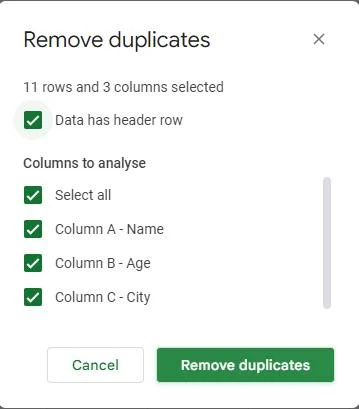
Dialoogiboksi „Duplikaatide eemaldamine” allservast leiate nupu „Eemalda duplikaadid”. Klõpsake sellel nupul.
Pärast nupul „Eemalda duplikaadid” klõpsamist töötleb Google'i arvutustabelid teie taotlust. Veerud kontrollitakse ja kõik nendes veergudes duplikaatväärtustega read eemaldatakse, kõrvaldades edukalt duplikaadid.
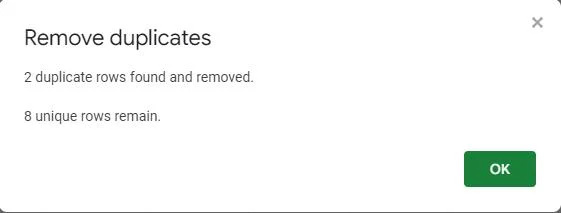
Hüpikaken kinnitab, et dubleeritud väärtused on tabelist eemaldatud. See näitab, et leiti ja eemaldati kaks dubleerivat rida, jättes tabelisse kaheksa kordumatut kirjet.
Pärast funktsiooni „Duplikaatide eemaldamine” kasutamist värskendatakse meie tabelit järgmiselt.
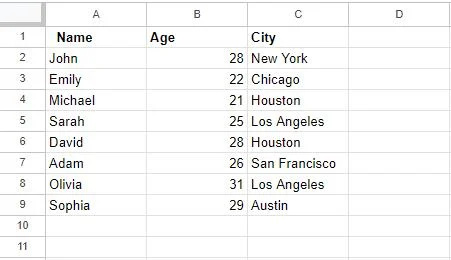
Oluline märkus, mida siinkohal arvesse võtta, on see, et duplikaatide eemaldamine selle funktsiooni abil on püsiv toiming. Duplikaatread kustutatakse teie andmekogumist ja te ei saa seda toimingut tagasi võtta, kui teil pole andmete varukoopiat. Seega veenduge, et olete valinud duplikaatide leidmiseks õiged veerud, kontrollides oma valikut kaks korda.
2. meetod: Unikaalse funktsiooni kasutamine duplikaatide eemaldamiseks
Teine meetod, mida me siin arutame, on kasutada UNIKAALNE funktsioon Google'i arvutustabelites. The UNIKAALNE funktsioon hangib kindlaksmääratud andmevahemikust või veerust erinevad väärtused. Kuigi see ei eemalda otse algandmetest duplikaate, loob see ainulaadsete väärtuste loendi, mida saate kasutada andmete teisendamiseks või analüüsimiseks ilma duplikaatideta.
Loome selle meetodi mõistmiseks näite.
Kasutame tabelit, mis loodi selle õpetuse algosas. Nagu me juba teame, sisaldab tabel teatud andmeid, mis on dubleeritud. Niisiis, oleme valinud lahtri 'E2', kuhu kirjutada UNIKAALNE valem sisse. Meie kirjutatud valem on järgmine:
=UNIKALNE(A2:A11)
Google'i arvutustabelites kasutamisel hangib UNIQUE valem unikaalsed väärtused eraldi veerus. Seega oleme selle valemi varustanud vahemikuga alates lahtrist A2 juurde A11 , mida rakendatakse veerus A. Seega eraldab see valem veerust kordumatud väärtused A ja kuvab need veerus, kuhu valem on kirjutatud.
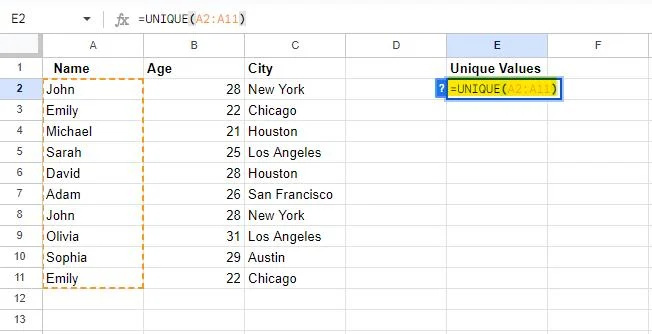
Valem rakendatakse määratud vahemikule, kui vajutate sisestusklahvi.
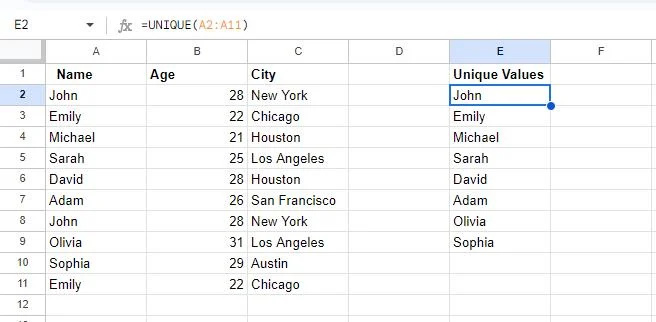
Sellel pildil näeme, et kaks lahtrit on tühjad. Selle põhjuseks on asjaolu, et tabelis on dubleeritud kaks väärtust, nimelt John ja Emily. The UNIKAALNE funktsioon kuvab igast väärtusest ainult ühe eksemplari.
See meetod ei eemaldanud dubleeritud väärtusi otse määratud veerust, vaid lõi teise veeru, et anda meile selle veeru kordumatud kirjed, kõrvaldades duplikaadid.
Järeldus
Duplikaatide eemaldamine Google'i arvutustabelites on kasulik meetod andmete analüüsimiseks. Selles juhendis on näidatud kaks meetodit, mis võimaldavad teil hõlpsasti oma andmetest duplikaatkirjeid eemaldada. Esimene meetod selgitas Google'i arvutustabelite kasutamist duplikaatfunktsiooni eemaldamiseks. See meetod skannib määratud lahtrivahemikku ja kõrvaldab duplikaadid. Teine meetod, mida oleme arutanud, on kasutada dubleeritud väärtuste hankimiseks valemit. Kuigi see ei eemalda otseselt vahemikust duplikaate, kuvab see selle asemel unikaalsed väärtused uues veerus.