R-is on veergude arvu hankimine põhitoiming, mida on DataFramesiga töötamisel vaja paljudes olukordades. Andmete alamhulga koostamisel, analüüsimisel, manipuleerimisel, avaldamisel ja visualiseerimisel on veergude arv väga oluline teada. Seetõttu pakub R erinevaid lähenemisviise määratud DataFrame'i veergude kogusumma saamiseks. Selles artiklis käsitleme mõningaid lähenemisviise, mis aitavad meil DataFrame'i veergude arvu saada.
Näide 1: Funktsiooni Ncol() kasutamine
ncol() on kõige sagedasem funktsioon DataFramesi veergude kogusumma saamiseks.
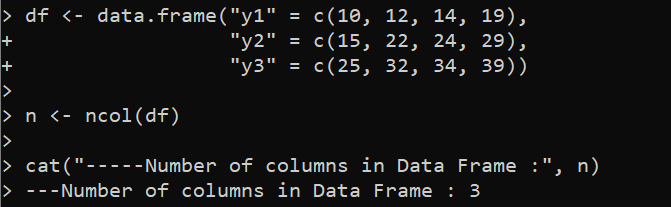
df <- data.frame('y1' = c(10, 12, 14, 19),
'y2' = c(15, 22, 24, 29),
'y3' = c(25, 32, 34, 39))
n <- ncol(df)
cat('-----veergude arv andmeraamis :', n)
Selles näites loome esmalt kolme veeruga 'df' DataFrame'i, mis on tähistatud kui 'y1', 'y2' ja 'y3', kasutades R-i funktsiooni data.frame(). Iga veeru elemendid on määratud kasutades funktsioon c(), mis loob elementide vektori. Seejärel kasutatakse muutujat 'n' kasutades funktsiooni ncol () veergude koguarvu määramiseks 'df' DataFrame'is. Lõpuks prindib funktsioon cat() koos kirjeldava sõnumi ja muutujaga „n” tulemused konsoolile.
Nagu oodatud, näitab allalaaditud väljund, et määratud DataFrame'il on kolm veergu:
Näide 2: loendage tühja andmeraami veergude koguarv
Järgmisena rakendame tühjale DataFrame'ile funktsiooni ncol (), mis saab ka veergude koguväärtused, kuid see väärtus on null.
tühi_df <- data.frame()n <- ncol(tühi_df)
cat('---Veerud andmeraamis :', n)
Selles näites genereerime tühja DataFrame'i, 'empty_df', kutsudes välja data.frame() veerge või ridu määramata. Järgmisena kasutame funktsiooni ncol(), mida kasutatakse DataFrame'i veergude arvu leidmiseks. Funktsioon ncol () on siin seatud 'empty_df' DataFrame'iga, et saada veergude kogusumma. Kuna andmeraam 'empty_df' on tühi, pole sellel ühtegi veergu. Seega on ncol(empty_df) väljund 0. Tulemused kuvatakse siin juurutatud funktsiooni cat() abil.
Väljund näitab ootuspäraselt väärtust '0', kuna DataFrame on tühi.

Näide 3: Funktsiooni Select_If() kasutamine funktsiooniga Length()
Kui tahame hankida mis tahes kindlat tüüpi veergude arvu, peaksime kasutama funktsiooni select_if() koos funktsiooni R long() funktsiooniga. Neid funktsioone kasutatakse kombineerituna, et saada iga tüübi veergude kogusumma. . Nende funktsioonide kasutamiseks mõeldud kood on realiseeritud järgmiselt:
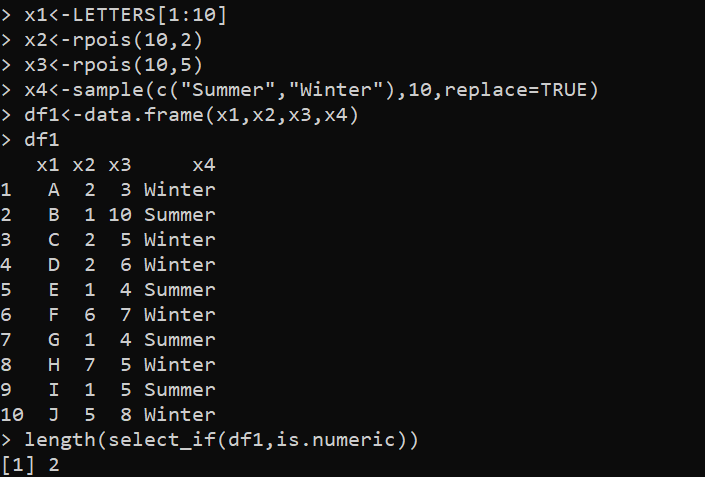
raamatukogu (dplyr)x1<-TÄHED[1:10]
x2<-rpois(10,2)
x3<-rpois(10,5)
x4<-sample(c('Suvi','Talv'),10,asendada=TRUE)
df1<-data.frame(x1,x2,x3,x4)
df1
pikkus(select_if(df1,is.numbriline))
Selles näites laadime esmalt paketi dplyr, et saaksime juurdepääsu funktsioonidele select_if() ja funktsioonile length(). Seejärel loome neli muutujat – vastavalt “x1”, “x2”, “x3” ja “x4”. Siin sisaldab “x1” ingliskeelse tähestiku 10 esimest suurtähte. Muutujad “x2” ja “x3” genereeritakse funktsiooni rpois() abil, et luua kaks eraldi 10 juhuslikust numbrist koosnevat vektorit vastavalt parameetritega 2 ja 5. Muutuja “x4” on 10 elemendiga faktorivektor, mis on valitud vektorist c juhuslikult (“suvi”, “talv”).
Seejärel proovime luua 'df1' DataFrame'i, kus kõik muutujad edastatakse funktsioonis data.frame(). Lõpuks käivitame funktsiooni length(), et määrata 'df1' DataFrame'i pikkus, mis luuakse dplyr-paketi funktsiooni select_if() abil. Funktsioon select_if() valib argumendina veerud andmeraamist 'df1' ja funktsioon is.numeric() valib ainult need veerud, mis sisaldavad arvväärtusi. Seejärel saab funktsioon long() veergude kogusumma, mis on valitud valikuga select_if(), mis on kogu koodi väljund.
Veeru pikkus on näidatud järgmises väljundis, mis näitab DataFrame'i veergude koguarvu:
Näide 4: Funktsiooni Sapply() kasutamine
Ja vastupidi, kui tahame ainult veergude puuduvaid väärtusi lugeda, on meil funktsioon sapply (). Funktsioon apply() itereerib iga DataFrame'i veeru, et töötada konkreetselt. Funktsioon apply() edastatakse esmalt argumendina DataFrame'iga. Seejärel tuleb selle DataFrame'iga toiming teha. Funktsiooni sapply() rakendamine DataFrame'i veergudes olevate NA väärtuste arvu saamiseks on esitatud järgmiselt.
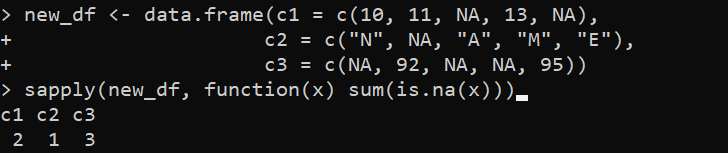
new_df <- data.frame(c1 = c(10, 11, NA, 13, NA),c2 = c('N', NA, 'A', 'M', 'E'),
c3 = c(NA, 92, NA, NA, 95))
sapply(new_df, function(x) sum(is.na(x)))
Selles näites genereerime kolme veeruga andmeraami 'new_df' – 'c1', 'c2' ja 'c3'. Esimesed veerud “c1” ja “c3” sisaldavad arvväärtusi, sealhulgas mõningaid puuduvaid väärtusi, mida tähistab NA. Teine veerg “c2” sisaldab märke, sealhulgas mõningaid puuduvaid väärtusi, mida tähistab ka NA. Seejärel rakendame funktsiooni sapply() andmeraamile 'new_df' ja arvutame igas veerus puuduvate väärtuste arvu, kasutades sum() avaldist funktsiooni sapply() sees.
Funktsioon is.na() on avaldis, mis on määratud funktsioonile summa() ja mis tagastab loogilise vektori, mis näitab, kas iga element veerus puudub või mitte. Funktsioon summa() liidab TRUE väärtused, et lugeda igas veerus puuduvate väärtuste arv.
Seega kuvatakse väljundis NA koguväärtused igas veerus:
Näide 5: funktsiooni Dim() kasutamine
Lisaks tahame saada veergude koguarvu koos DataFrame'i ridadega. Seejärel annab funktsioon dim() DataFrame'i mõõtmed. Funktsioon dim() võtab objekti argumendina, mille mõõtmeid tahame tuua. Siin on kood funktsiooni dim() kasutamiseks:
d1 <- data.frame(team=c('t1', 't2', 't3', 't4'),punktid=c(8, 10, 7, 4))
hämar (d1)
Selles näites määratleme esmalt d1 DataFrame'i, mis luuakse funktsiooni data.frame() abil, kus kaks veergu on seatud 'meeskond' ja 'punktid'. Pärast seda käivitame funktsiooni dim () üle DataFrame'i d1. Funktsioon dim() tagastab DataFrame'i ridade ja veergude arvu. Seega, kui käivitame dim(d1), tagastab see kahe elemendiga vektori – millest esimene peegeldab ridade arvu d1 DataFrame'is ja teine veergude arvu.
Väljund tähistab DataFrame'i mõõtmeid, kus väärtus '4' näitab veergude koguarvu ja väärtus '2' tähistab ridu:

Järeldus
Nüüd saime teada, et veergude arvu loendamine R-is on lihtne ja oluline toiming, mida saab DataFrame'is teha. Kõigist funktsioonidest on funktsioon ncol() kõige mugavam viis. Nüüd oleme tuttavad erinevate viisidega, kuidas antud DataFrame'ist veergude arvu hankida.