UTF-8 tähendab ' Unicode'i teisendusvorming 8-bitine ” ja vastab suurepärasele kodeerimisvormingule, mis tagab märkide õige kuvamise kõigis seadmetes, olenemata kasutatavast keelest/skriptist. Samuti on see vorming abistav veebilehtede jaoks ning seda kasutatakse tekstiandmete salvestamiseks, töötlemiseks ja edastamiseks Internetis.
See õpetus hõlmab alltoodud sisuvaldkondi.
- Mis on UTF-8 kodeering?
- Kuidas UTF-8 kodeering töötab?
- Kuidas koodipunktide väärtusi arvutatakse?
- Kuidas kodeerida/dekodeerida UTF-8 JavaScriptis?
- UTF-8 kodeerimine/dekodeerimine JavaScriptis, kasutades meetodeid „encodeURIComponent()” ja „decodeURIComponent()”.
- UTF-8 kodeerimine/dekodeerimine JavaScriptis, kasutades meetodeid 'encodeURI()' ja 'decodeURI()'.
- UTF-8 kodeerimine/dekodeerimine JavaScriptis regulaaravaldiste abil.
- Järeldus
Mis on UTF-8 kodeering?
“ UTF-8 kodeering ” on protseduur Unicode'i märkide jada teisendamiseks kodeeritud stringiks, mis sisaldab 8-bitisi baite. See kodeering võib teiste märgikodeeringutega võrreldes esindada suurt valikut märke.
Kuidas UTF-8 kodeering töötab?
UTF-8-s sümboleid esindades on iga üksiku koodipunkt esindatud ühe või mitme baidiga. Järgmine on ASCII-vahemiku koodipunktide jaotus:
- Üks bait tähistab koodipunkte ASCII vahemikus (0–127).
- Kaks baiti tähistavad koodipunkte ASCII vahemikus (128-2047).
- Kolm baiti esindavad koodipunkte ASCII vahemikus (2048-65535).
- Neli baiti esindavad koodipunkte ASCII vahemikus (65536-1114111).
See on selline, et esimene bait UTF-8 'järjestust nimetatakse ' juhtbait ”, mis annab teavet jada baitide arvu ja märgi koodipunkti väärtuse kohta.
Ühe-, kahe-, kolme- ja neljabaidise jada juhtbait on vastavalt vahemikus (0–127), (194–233), (224–239) ja (240–247).
Järjekorras olevaid ülejäänud baite nimetatakse ' järel ” baiti. Kahe-, kolme- ja neljabaidise jada baidid on kõik vahemikus (128–191). See on selline, et märgi koodipunkti väärtust saab arvutada, analüüsides algus- ja lõpubaite.
Kuidas koodipunktide väärtusi arvutatakse?
Erinevate baidijadade koodipunktide väärtused arvutatakse järgmiselt:
- Kahebaidine jada: Koodipunkt on samaväärne '((lb – 194) * 64) + (tb – 128)'.
- Kolmebaidine jada : koodipunkt on samaväärne väärtusega „((lb – 224) * 4096) + ((tb1 – 128) * 64) + (tb2 – 128)”.
- Neljabaidine jada : koodipunkt on samaväärne väärtusega „((lb – 240) * 262144) + ((tb1 – 128) * 4096) + ((tb2 – 128) * 64) + (tb3 – 128)”.
Kuidas kodeerida/dekodeerida UTF-8 JavaScriptis?
UTF-8 kodeerimist ja dekodeerimist JavaScriptis saab läbi viia alltoodud lähenemisviiside abil:
- “ enodeURIComponent() ” ja „ decodeURIComponent() ” Meetodid.
- “ encodeURI() ” ja „ decodeURI() ” Meetodid.
- Regulaaravaldised.
1. lähenemisviis: UTF-8 kodeerimine/dekodeerimine JavaScriptis, kasutades meetodeid „encodeURIComponent()” ja „decodeURIComponent()”
' encodeURIComponent() ” meetod kodeerib URI komponenti. Samuti saab see kodeerida erimärke, nagu @, &, :, +, $, # jne. decodeURIComponent() ” meetod aga dekodeerib URI komponendi. Neid meetodeid saab kasutada edastatud väärtuste kodeerimiseks ja dekodeerimiseks vastavalt UTF-8-le.
Süntaks (meetod 'encodeURIComponent()')
encodeURIComponent ( x )Antud süntaksis ' x ” tähistab kodeeritavat URI-d.
Tagastusväärtus
See meetod tõi välja kodeeritud URI stringina.
Süntaks (meetod 'decodeURIComponent()')
decodeURIComponent ( x )Siin, ' x ” viitab dekodeeritavale URI-le.
Tagastusväärtus
See meetod annab dekodeeritud URI.
Näide 1: UTF-8 kodeerimine JavaScriptis
See näide kodeerib edastatud stringi kodeeritud UTF-8 väärtuseks kasutaja määratud funktsiooni abil:
tagasi põgeneda ( encodeURIComponent ( x ) ) ;
}
las val = 'siin' ;
konsool. logi ( 'Antud väärtus ->' + val ) ;
lase kodeeridaVal = encode_utf8 ( val ) ;
konsool. logi ( 'Kodeeritud väärtus -> ' + kodeeri Val ) ;
Nendel koodiridadel tehke alltoodud samme.
- Esiteks määrake funktsioon ' encode_utf8() ”, mis kodeerib määratud parameetriga esitatud edastatud stringi.
- Selle kodeerimise teeb ' encodeURIComponent() ” meetod funktsiooni definitsioonis.
- Märge: ' unescape () ” meetod asendab mis tahes paojärjestuse selle tähistatava märgiga.
- Pärast seda lähtestage kodeeritav väärtus ja kuvage see.
- Nüüd käivitage määratletud funktsioon ja edastage määratletud märgikombinatsioon selle argumentidena, et kodeerida see väärtus UTF-8-ga.
Väljund
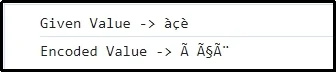
Siin võib vihjata, et üksikud märgid on vastavalt UTF-8-s esindatud ja kodeeritud.
Näide 2: UTF-8 dekodeerimine JavaScriptis
Allolev koodiesitlus dekodeerib edastatud väärtuse (märkide kujul) kodeeritud UTF-8 esituseks:
tagasi decodeURIComponent ( põgeneda ( x ) ) ;
}
las val = 'çè' ;
konsool. logi ( 'Antud väärtus ->' + val ) ;
lase dekodeerida = decode_utf8 ( val ) ;
konsool. logi ( 'Dekodeeritud väärtus -> ' + dekodeerida ) ;
Selles koodiplokis:
- Samuti määrake funktsioon ' decode_utf8() ', mis dekodeerib läbitud märgikombinatsiooni '' kaudu decodeURIComponent() ” meetod.
- Märge: ' põgeneda () ” meetod hangib uue stringi, milles erinevad märgid asendatakse kuueteistkümnendsüsteemi paojärjestustega.
- Pärast seda määrake dekodeeritavate märkide kombinatsioon ja avage määratletud funktsioon, et UTF-8-le sobivalt dekodeerida.
Väljund

Siin võib viidata sellele, et eelmises näites kodeeritud väärtus dekodeeritakse vaikeväärtuseks.
2. lähenemisviis: UTF-8 kodeerimine/dekodeerimine JavaScriptis, kasutades meetodeid „encodeURI()” ja „decodeURI()”
' encodeURI() ” kodeerib URI-d, asendades iga mitme märgi eksemplari mitme paojärjestusega, mis esindavad märgi UTF-8 kodeeringut. Võrreldes ' encodeURIComponent() ” meetod, see konkreetne meetod kodeerib piiratud tähemärke.
' decodeURI() ” meetod aga dekodeerib URI(kodeeritud). Neid meetodeid saab rakendada kombineeritult, et kodeerida ja dekodeerida UTF-8 kodeeritud väärtuses olevate tähemärkide kombinatsiooni.
Süntaks(encodeURI() meetod)
encodeURI ( x )Ülaltoodud süntaksis ' x ” vastab URI-na kodeeritavale väärtusele.
Tagastusväärtus
See meetod hangib kodeeritud väärtuse stringi kujul.
Süntaks(decodeURI() meetod)
decodeURI ( x )Siin, ' x ” tähistab dekodeeritavat kodeeritud URI-d.
Tagastusväärtus
See tagastab dekodeeritud URI stringina.
Näide 1: UTF-8 kodeerimine JavaScriptis
See esitlus kodeerib edastatud märgikombinatsiooni kodeeritud UTF-8 väärtuseks:
tagasi põgeneda ( encodeURI ( x ) ) ;
}
las val = 'siin' ;
konsool. logi ( 'Antud väärtus ->' + val ) ;
lase kodeeridaVal = encode_utf8 ( val ) ;
konsool. logi ( 'Kodeeritud väärtus -> ' + kodeeri Val ) ;
Siinkohal tuletage meelde lähenemisviise kodeerimiseks eraldatud funktsiooni määratlemiseks. Nüüd rakendage meetodit 'encodeURI()', et esitada edastatud tähemärkide kombinatsioon UTF-8 kodeeritud stringina. Pärast seda määrake samuti hinnatavad märgid ja käivitage määratletud funktsioon, edastades määratletud väärtuse kodeeringu teostamiseks selle argumentidena.
Väljund
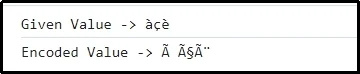
Siin on ilmne, et läbitud märgikombinatsioon on edukalt kodeeritud.
Näide 2: UTF-8 dekodeerimine JavaScriptis
Alltoodud koodiesitlus dekodeerib kodeeritud UTF-8 väärtuse (eelmises näites):
tagasi decodeURI ( põgeneda ( x ) ) ;
}
las val = 'çè' ;
konsool. logi ( 'Antud väärtus ->' + val ) ;
lase dekodeerida = decode_utf8 ( val ) ;
konsool. logi ( 'Dekodeeritud väärtus -> ' + dekodeerida ) ;
Selle koodi järgi deklareerige funktsioon ' decode_utf8() ', mis sisaldab määratud parameetrit, mis esindab tähemärkide kombinatsiooni, mida dekodeerida kasutades ' decodeURI() ” meetod. Nüüd määrake dekodeeritav väärtus ja käivitage määratletud funktsioon, et rakendada dekodeerimine ' UTF-8 ” esindus.
Väljund
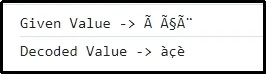
See tulemus tähendab, et eelnevalt kodeeritud väärtus otsustatakse vastavalt.
3. lähenemisviis: UTF-8 kodeerimine/dekodeerimine JavaScriptis regulaaravaldiste abil
See lähenemisviis rakendab kodeeringut nii, et mitmebaidine unicode string kodeeritakse UTF-8 mitme ühebaidise tähemärgiga. Samamoodi toimub dekodeerimine nii, et kodeeritud string dekodeeritakse tagasi mitmebaidilisteks Unicode'i tähemärkideks.
Näide 1: UTF-8 kodeerimine JavaScriptis
Allolev kood kodeerib mitmebaidise unicode-stringi UTF-8 ühebaidilisteks tähemärkideks:
kui ( tüüp val != 'string' ) viskama uus Tüübiviga ( 'Parameeter' val 'ei ole string' ) ;
konst string_utf8 = val. asendada (
/[\u0080-\u07ff]/g , // U+0080 – U+07FF => 2 baiti 110yyyyyy, 10zzzzzz
funktsiooni ( x ) {
oli välja = x. charCodeAt ( 0 ) ;
tagasi String . CharCode'ist ( 0xc0 | välja >> 6 , 0x80 | välja & 0x3f ) ; }
) . asendada (
/[\u0800-\uffff]/g , // U+0800 – U+FFFF => 3 baiti 1110xxxx, 10yyyyyy, 10zzzzzz
funktsiooni ( x ) {
oli välja = x. charCodeAt ( 0 ) ;
tagasi String . CharCode'ist ( 0xe0 | välja >> 12 , 0x80 | välja >> 6 & 0x3F , 0x80 | välja & 0x3f ) ; }
) ;
konsool. logi ( 'Kodeeritud väärtus regulaaravaldist kasutades ->' + string_utf8 ) ;
}
kodeeridaUTF8 ( 'siin' )
Selles koodilõigus:
- Määratlege funktsioon ' kodeeri UTF8() ', mis sisaldab parameetrit, mis tähistab väärtust, mis tuleb kodeerida kui ' UTF-8 ”.
- Selle määratluses kontrollige läbitud väärtust, mis ei ole string, kasutades ' tüüp ' operaator ja tagastage määratud kohandatud erand käsu '' kaudu viskama ” märksõna.
- Pärast seda rakendage ' charCodeAt() ” ja „ fromCharCode() ” meetodid stringi esimese märgi Unicode'i hankimiseks ja antud Unicode'i väärtuse vastavalt tähemärkideks teisendamiseks.
- Lõpuks käivitage määratletud funktsioon, edastades etteantud märgijada, et kodeerida see väärtus kui ' UTF-8 ” esindus.
Väljund

See väljund näitab, et kodeering on tehtud õigesti.
Näide 2: UTF-8 dekodeerimine JavaScriptis
Selles demonstratsioonis dekodeeritakse tähemärkide jada ' UTF-8 'esitus:
kui ( tüüp val != 'string' ) viskama uus Tüübiviga ( 'Parameeter' val 'ei ole string' ) ;
konst str = val. asendada (
/[\u00e0-\u00ef][\u0080-\u00bf][\u0080-\u00bf]/g ,
funktsiooni ( x ) {
oli välja = ( ( x. charCodeAt ( 0 ) & 0x0f ) << 12 ) | ( ( x. charCodeAt ( 1 ) & 0x3f ) << 6 ) | ( x. charCodeAt ( 2 ) & 0x3f ) ;
tagasi String . CharCode'ist ( välja ) ; }
) . asendada (
/[\u00c0-\u00df][\u0080-\u00bf]/g ,
funktsiooni ( x ) {
oli välja = ( x. charCodeAt ( 0 ) & 0x1f ) < '+str);
}
decodeUTF8('çè')
Selles koodis:
- Samamoodi määratlege funktsioon ' dekodeeridaUTF8() ”, millel on parameeter, mis viitab dekodeeritavale edastatud väärtusele.
- Kontrollige funktsiooni definitsioonis edastatud väärtuse stringi tingimust ' tüüp ” operaator.
- Nüüd rakendage ' charCodeAt() ” meetod, et hankida vastavalt esimese, teise ja kolmanda stringi tähemärgi Unicode.
- Samuti rakendage ' String.fromCharCode() ” meetod Unicode'i väärtuste tähemärkideks muutmiseks.
- Samamoodi korrake seda protseduuri uuesti, et hankida esimese ja teise stringi märgi Unicode ja muuta need unicode'i väärtused tähemärkideks.
- Lõpuks avage UTF-8 dekodeeritud väärtuse tagastamiseks määratletud funktsioon.
Väljund

Siin saab kontrollida, kas dekodeerimine on õigesti tehtud.
Järeldus
UTF-8 esituses kodeerimist/dekodeerimist saab läbi viia ' enodeURIComponent()” ja ' decodeURIComponent() meetodid, ' encodeURI() ” ja „ decodeURI() ” meetodid või regulaaravaldiste kasutamine.