Amazon Redshift on AWS-i pakutav pilvelahendus, mis täidab andmelao eesmärki. Andmeladu on pilves suur ruum, mis salvestab tohutul hulgal andmeid. Andmelao ja andmebaasi erinevus seisneb selles, et esimene ei salvesta ainult jooksvaid andmeid, vaid ka andmete täielikku ajalugu.
Sellest artiklist saate teada AWS-i Amazon Redshifti ja selle teenuse toetatavate andmetüüpide kohta.
Mis on Amazon RedShift?
See on pilvelahendus andmelao jaoks, mis põhineb 'PostgreSQL' . See kasutab tehnoloogiat nn 'Massiivselt paralleelne töötlemine (MPP)' petabaitide andmete töötlemiseks välkkiirelt. See pakub lihtsat lahendust reaalajas prognoosimiseks, mis põhineb ajaloolistel andmetel ja voogedastuslahendustel.
Järgmine joonis näitab Amazon Redshifti töömehhanismi:
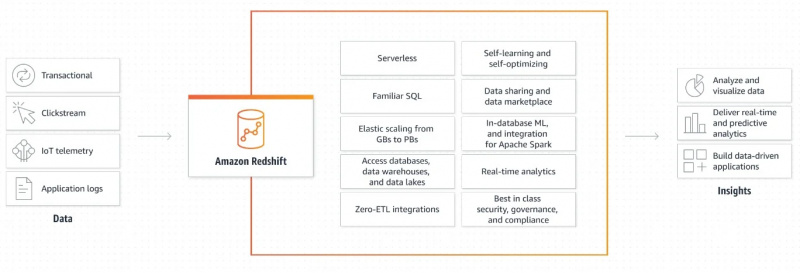
See graafiline selgitus, kuidas Amazon Redshift töötab, on väga lihtne ja selge. See annab meile teavet selle kohta, kuidas andmeid hangitakse ja töödeldakse, et luua väljundeid ja luua andmepõhiseid rakendusi.
Amazon Redshifti andmelao arhitektuuri on näha ka alloleval joonisel:
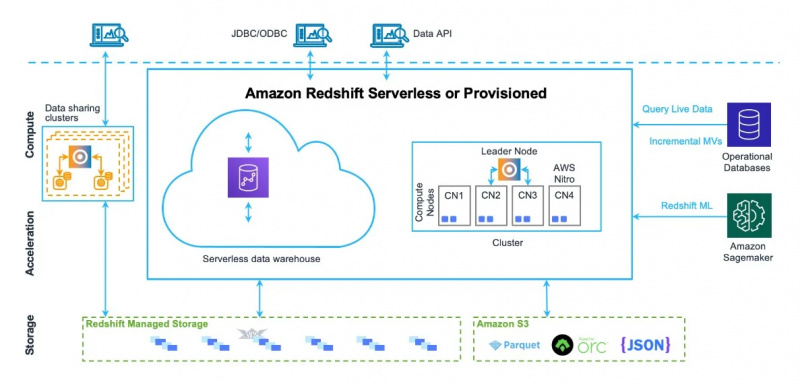
Nüüd käsitleme selle teenuse kasutusvõimalusi ja funktsioone.
Funktsioonid
Nagu juba mainitud, põhineb Amazon Redshift PostgreSQL-il ja kasutab tehnoloogiat nimega Massively Parallel Processing, mis võimaldab tal kiiresti töödelda petabaite andmeid. Seetõttu pakub Redshift palju funktsioone ja kasutusvõimalusi. Mõned neist funktsioonidest on allpool:
- Andmete turvalisus ja krüpteerimine.
- Ärianalüüs.
- Andmepõhiste rakenduste tugi.
- Ennustav analüüs.
- Automatiseeritud ülesannete kordamine.
- Samaaegne andmete skaleerimine.
- Andmeladustamine.
Mõned selle teenuse lisafunktsioonid on näha alloleval joonisel:
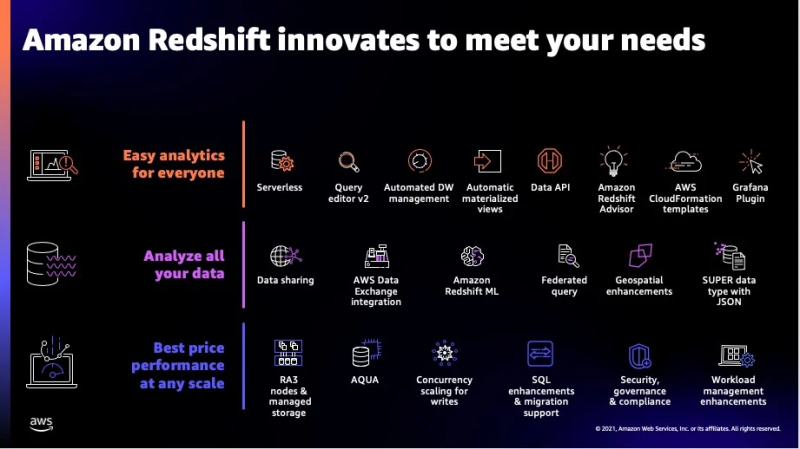
Need olid enamik Redshifti pakutavatest funktsioonidest ja nüüd läheme üle selle teenuse toetatavatele andmetüüpidele.
Andmetüübid
Amazon Redshift on andmehoidla lahendus, millel on palju funktsioone. See toetab nii struktureeritud kui ka struktureerimata andmetüüpe. Kuna see põhineb PostgreSQL-il, saab andmeid töödelda lihtsate SQL-päringute abil.
Nüüd tekib veel üks küsimus, st kuidas need andmevormingud üksteisest erinevad? Arutleme nende kahe andmevormingu üle.
Struktureeritud andmed
Väga vormindatud andmetüüpi, mida masinõppe algoritmid hõlpsasti tõlgivad, nimetatakse struktureeritud andmeteks. SQL-andmebaas töötab struktureeritud andmetega. Struktureeritud andmed on tabeli kujul, näiteks relatsiooniandmebaasides kasutatavad andmed
Üks laialdaselt kasutatavaid SQL-i andmebaasihaldussüsteeme on MYSQL. Selle arhitektuuri saab näha alloleval joonisel:
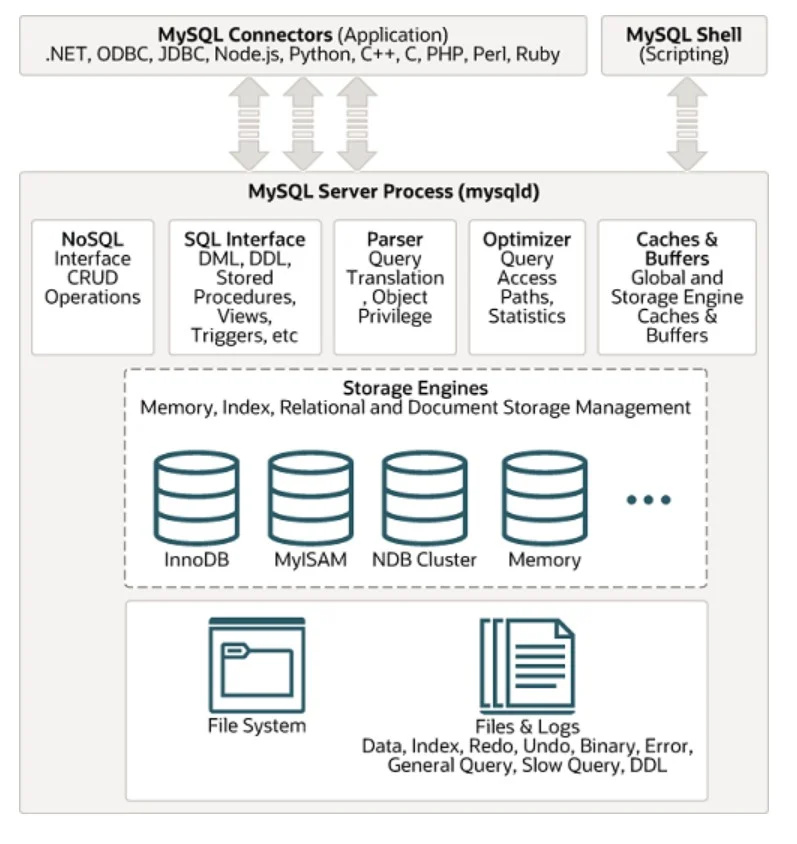
Struktureerimata andmed
Struktureerimata andmed on vähem mustriga ja vähem vormindatud, näiteks mitterelatsioonilistes andmebaasides kasutatavad andmed. MongoDB on kuulus mitterelatsiooniline andmebaas. SQL-päringud ei tööta mitterelatsioonilistes andmebaasides, seetõttu nimetatakse neid andmebaase ka NoSQL-i andmebaasideks.
Nagu juba mainitud, on MongoDB struktureerimata andmebaasihaldussüsteem ja selle arhitektuuri saab näha alloleval joonisel:
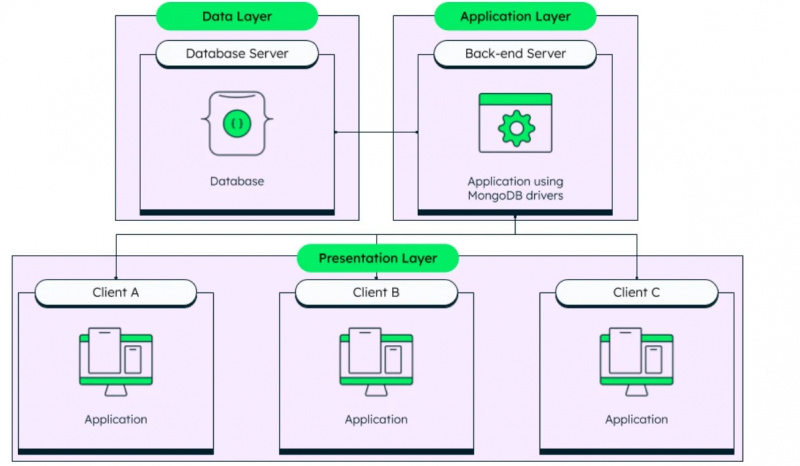
Oleme läbi vaadanud kaks andmebaasides kasutatavat põhiandmetüüpi ja liigume nüüd tegelike andmetüüpide juurde, mida Amazon Redshift toetab. Need andmetüübid on:
- Numbrilised andmed
- Tegelaste andmed
- Kuupäeva ja kellaaja andmed
- Boole'i andmed
- HLLSKETCH Andmed
- SUPER andmed
- ASENDUSandmed
Arutleme nende andmetüüpide üle:
Numbrilised andmed
See andmetüüp on iseenesestmõistetav. See toetab andmeid täisarvude, kümnendkohtade, ujukoma ja muude numbriliste andmetüüpide kujul.
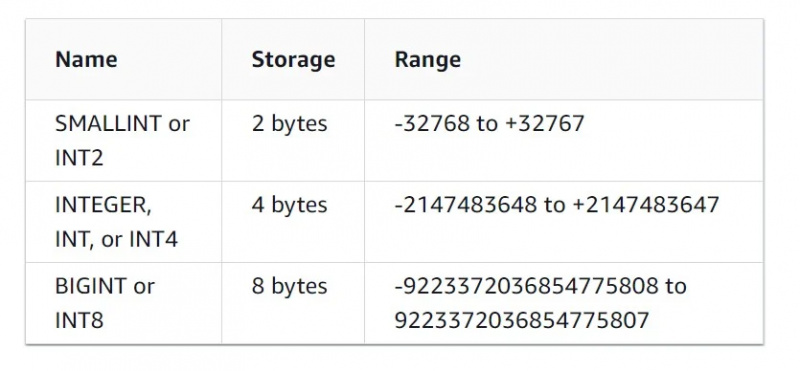
Täisarvulise andmetüübi omadused on näha alloleval joonisel:
Kümnendandmete tüüp salvestab andmed kasutaja täpsuse alusel. Selle omadused on järgmised:

Tegelaste andmed
CHAR ja VARCHAR andmetüübid kuuluvad märgipõhiste andmetüüpide kategooriasse. NCHAR ja NVARCHAR on ka märgi tüüpi andmetüübid. Erinevalt CHAR-ist ja VARCHAR-ist salvestavad need kaks andmetüüpi fikseeritud pikkusega Unicode-märke. Vaatame nende andmetüüpide omadusi, näiteks:
- CHAR, CHARACTER, NCHAR on vahemikus 4 kB.
- VARCHAR, NVARCHAR on vahemikus 64 KB.
- BPCHARi vahemik on 256 baiti.
- TEXT-i vahemik on 260 baiti.
Kuupäeva ja kellaaja andmed
Kuupäeva ja kellaaja andmetüübid on DATE, TIME, TIMETZ, TIMESTAMP, TIMESTAMPTZ. Nende andmetüüpide funktsionaalsed võimalused on järgmised:
- DATE salvestab lihtsalt kalendrikuupäevad.
- TIME salvestab aja ilma ühelegi ajavööndile viitamata. Vaikimisi on see UTC.
- TIMETZ salvestab aja ajavööndi alusel. Vaikimisi on see nii kasutaja- kui ka süsteemitabelites UTC.
- TIMESTAMP ei sisalda mitte ainult aega, vaid ka kuupäevi. Vaikimisi on see nii kasutaja- kui ka süsteemitabelites UTC.
- TIMESTAMPTZ ei sisalda mitte ainult aega, vaid ka kuupäevi. Vaikimisi on see UTC ainult kasutajatabelites.
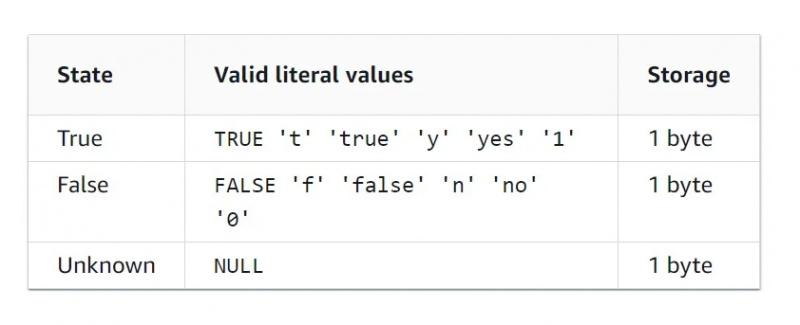
Boole'i andmed
Boole'i andmetüüp on binaarne andmetüüp, mis tähendab, et väärtusi on ainult kaks. Boole'i andmetüübi omaduste tabel on toodud alloleval joonisel:
HLLSKETCH Andmed
Seda andmetüüpi kasutatakse visandite salvestamiseks. Punane nihe võib kujutada visandeid kas hõredal või tihedal kujul. Visandid algavad hõredalt ja muutuvad järk-järgult tihedamaks, kui tihe vorming tagab linki järgides suurema tõhususe.
SUPER andmed
See andmetüüp käsitleb struktureerimata andmeid, mis võivad olla massiivide, pesastatud struktuuride või JSON-i kujul. Andmete mudelit ega vormingut pole. Kasutajad saavad lingil navigeerides rohkem teavet uurida.
ASENDUSandmed
See andmetüüp salvestab ka tähemärke. Pikkus on aga piiratud. Amazon Redshift võimaldab VARBYTE'i andmeid üle kanda mis tahes täisarvu tüüpi või märgi tüüpi andmetesse. Selle andmetüübi kohta lisateabe saamiseks järgige allolevat linki.
See on kõik, mis Amazon Redshiftis ja selle toetatavates andmetüüpides on.
Järeldus
Amazon Redshift on AWS-teenus, mis oma põhikujul täidab andmelao eesmärki, kuid on väga võimas ja funktsionaalne lahendus analüüsiks ja prognoosimiseks. Selles artiklis on käsitletud punanihet ja selle toetatavaid andmetüüpe. Neid andmetüüpe selgitati lühidalt koos nende omadustega.