Kuidas grupi liitmine MongoDB-s töötab?
Operaatorit $group tuleks kasutada sisenddokumentide rühmitamiseks vastavalt määratud _id avaldisele. Seejärel peaks see tagastama ühe dokumendi iga eraldi rühma koguväärtustega. Rakendamisega alustamiseks oleme MongoDB-s loonud kogumiku 'Raamat'. Pärast kogu “Raamatud” loomist oleme lisanud erinevate valdkondadega seotud dokumendid. Dokumendid sisestatakse kogusse meetodi insertMany() kaudu, nagu allpool on näidatud täidetav päring.
>db.Books.insertMany([{
_id:1,
pealkiri: 'Anna Karenina',
hind: 290,
aasta: 1879,
order_status: 'Laos',
autor: {
'nimi': 'Leo Tolstoi'
}
},
{
_id:2,
pealkiri: 'To Kill a Mockingbird',
hind: 500,
aasta: 1960,
order_status: 'out-of-stock',
autor: {
'nimi': 'Harper Lee'
}
},
{
_id:3,
pealkiri: 'Nähtamatu mees',
hind: 312,
aasta: 1953,
order_status: 'Laos',
autor: {
'nimi':'Ralph Ellison'
}
},
{
_id:4,
pealkiri: 'Armastatud',
hind: 370,
aasta: 1873,
order_status: 'out_of_stock',
autor: {
'nimi':'Toni Morrison'
}
},
{
_id:5,
pealkiri: 'Asjad lagunevad',
hind: 200,
aasta: 1958,
order_status: 'Laos',
autor: {
'nimi':'Chinua Achebe'
}
},
{
_id:6,
pealkiri: 'Lilla värv',
hind: 510,
aasta: 1982,
order_status: 'out-of-stock',
autor: {
'nimi':'Alice Walker'
}
}
])
Dokumendid salvestatakse edukalt raamatute kogusse ilma vigadeta, kuna väljund tunnistatakse tõeseks. Nüüd kasutame neid kogu “Raamatuid” dokumente “$group” liitmise teostamiseks.

Näide # 1: $group agregatsiooni kasutamine
Siin on näidatud $grupi liitmise lihtsat kasutamist. Koondpäring sisestab kõigepealt operaatori “$group”, seejärel kasutab operaator “$group” avaldisi rühmitatud dokumentide genereerimiseks.
>db.Books.aggregate([
{ $group:{ _id:'$autori.nimi'} }
])
Operaatori $group ülaltoodud päring on määratud väljaga „_id”, et arvutada kõigi sisenddokumentide koguväärtused. Seejärel eraldatakse väljale „_id” välja „$autori.nimi”, mis moodustab väljal „_id” erineva rühma. Dokumendi $author.name eraldi väärtused tagastatakse, kuna me ei arvuta akumuleeritud väärtusi. $group koondpäringu täitmisel on järgmine väljund. Väljal _id on autori.nimed väärtused.

Näide # 2: $group agregatsiooni kasutamine $push akumulaatoriga
$group agregatsiooni näide kasutab kõiki ülalmainitud akumulaatoreid. Kuid me saame kasutada akumulaatoreid $grupi koondamisel. Akumulaatorite operaatorid on need, mida kasutatakse sisenddokumendi väljadel, välja arvatud need, mis on rühmitatud _id all. Oletame, et tahame avaldise väljad massiivi suruda, siis kutsutakse välja akumulaator '$push' operaatoris '$group'. Näide aitab teil grupi '$push' akumulaatorit paremini mõista.
>db.Books.aggregate([
{ $grupp : { _id : '$_id', aasta: { $push: '$year' } } }
]
).ilus();
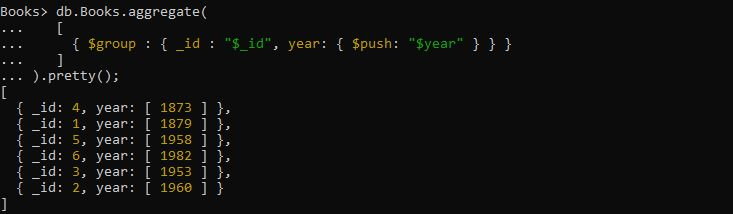
Siin tahame massiivi rühmitada antud raamatute avaldamisaasta kuupäeva. Selle saavutamiseks tuleks rakendada ülaltoodud päringut. Koondamispäring on varustatud avaldisega, kus operaator “$group” võtab väljaavaldise “_id” ja väljaavaldise “year”, et saada grupi aasta, kasutades $push-akumulaatorit. Sellest konkreetsest päringust hangitud väljund loob aastaväljade massiivi ja salvestab selle sisse tagastatud grupeeritud dokumendi.
Näide # 3: $group agregatsiooni kasutamine '$min' akumulaatoriga
Järgmiseks on meil akumulaator “$min”, mida kasutatakse $group agregatsioonis, et saada igast kogus olevast dokumendist minimaalne sobiv väärtus. Allpool on toodud $min akumulaatori päringuavaldis.
>db.Books.aggregate([{
$grupp:{
_id:{
pealkiri: '$title',
order_status: '$order_status'
},
minPrice:{$min: '$price'}
}
}
])
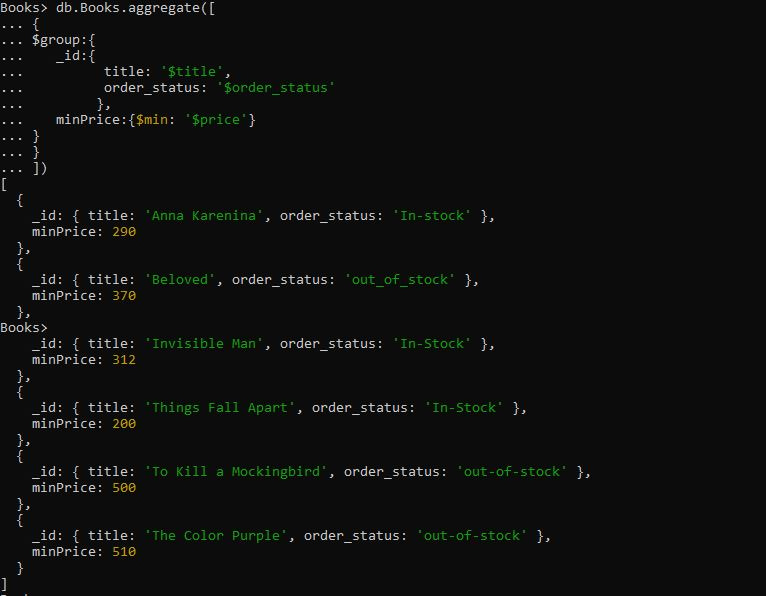
Päringul on koondamisavaldis “$group”, kuhu oleme rühmitanud dokumendi väljade “title” ja “order_status” jaoks. Seejärel esitasime $ min akumulaatori, mis rühmitas dokumendid, hankides rühmitamata väljadelt minimaalse hinna väärtused. Kui käivitame selle alloleva $min akumulaatori päringu, tagastab see järjestuses grupeeritud dokumendid pealkirja ja order_status järgi. Esimesena kuvatakse miinimumhind ja viimasena asetatakse dokumendi kõrgeim hind.
Näide # 4: kasutage $grupi liitmist koos $sum akumulaatoriga
Kõigi numbriväljade summa saamiseks, kasutades operaatorit $group, juurutatakse toiming $sum accumulator. See akumulaator võtab arvesse kogude mittenumbrilisi väärtusi. Lisaks kasutame siin $match agregatsiooni koos $group agregatsiooniga. $match agregaat aktsepteerib dokumendis antud päringu tingimusi ja edastab sobitatud dokumendi $group agregatsioonile, mis seejärel tagastab iga rühma dokumendi summa. $ summa akumulaatori jaoks on päring esitatud allpool.
>db.Books.aggregate([{ $match:{ order_status:'Laos'}},
{ $group:{ _id:'$autori.nimi', koguraamatud: { $summa:1 } }
}])
Ülaltoodud koondamispäring algab operaatoriga $match, mis vastab kõigile 'order_status'-le, mille olek on 'Laos' ja edastatakse sisendina $-rühmale. Seejärel on operaatoril $group avaldis $sum accumulator, mis väljastab kõigi laos olevate raamatute summa. Pange tähele, et '$summa:1' lisab 1 igale samasse rühma kuuluvale dokumendile. Siin näitas väljund ainult kahte rühmitatud dokumenti, millel on „tellimuse olek” seotud väärtusega „Laos”.

Näide # 5: kasutage $group agregatsiooni koos $sort agregatsiooniga
Operaatorit $group kasutatakse siin koos operaatoriga '$sort', mida kasutatakse rühmitatud dokumentide sortimiseks. Järgmisel päringul on sortimistoiminguks kolm etappi. Esiteks on $match etapp, seejärel $group etapp ja viimane on $sort-etapp, mis sorteerib rühmitatud dokumendi.
>db.Books.aggregate([{ $match:{ order_status:'out-of-stock'}},
{ $group:{ _id:{ autoriName :'$autori.nimi'}, totalBooks: { $sum:1} } },
{ $sort:{ autoriName:1}}
])
Siin oleme toonud sobitatud dokumendi, mille „tellimuse_olek” on otsas. Seejärel sisestatakse sobitatud dokument $group etapis, mis rühmitas dokumendi väljadega “authorName” ja “totalBooks”. Avaldis $group on seotud akumulaatoriga $summa laost otsas olevate raamatute koguarvuga. Seejärel sorteeritakse rühmitatud dokumendid $sort avaldisega kasvavas järjekorras, kuna '1' tähistab siin kasvavat järjekorda. Määratud järjekorras sorteeritud rühmadokument saadakse järgmises väljundis.

Näide # 6: Kasutage eraldiseisva väärtuse jaoks $group agregatsiooni
Koondamisprotseduur rühmitab dokumendid ka üksuste kaupa, kasutades operaatorit $group, et eraldada erinevad üksuste väärtused. Olgu meil selle avalduse päringuavaldis MongoDB-s.
>db.Books.aggregate( [ { $group : { _id : '$title' } } ] ).pretty();Koondamispäring rakendatakse kogule Books, et saada rühmadokumendi eristatav väärtus. Siinne rühm $ võtab avaldise _id, mis väljastab erinevad väärtused, kuna oleme sellele sisestanud välja 'pealkiri'. Rühmadokumendi väljund saadakse selle päringu käivitamisel, mille pealkirjade nimede rühm on väljal _id.

Järeldus
Juhendi eesmärk oli selgitada välja $group agregatsioonioperaatori kontseptsioon dokumendi rühmitamiseks MongoDB andmebaasis. MongoDB koondkäsitlus parandab rühmitamisnähtusi. Näidisprogrammidega demonstreeritakse operaatori $group süntaksi struktuuri. Lisaks $group operaatorite põhinäidetele oleme kasutanud seda operaatorit ka mõne akumulaatoriga nagu $push, $min, $sum ja sellistega nagu $match ja $sort.