'Pythonis kasutatakse teabe salvestamiseks võtme-väärtuste paaridena andmestruktuuri, mida nimetatakse sõnastikuks. Sõnastikuobjektid on optimeeritud andmete/väärtuste eraldamiseks, kui võti või võtmed on teada. Pidage meeles, et sõnaraamatud võivad sisaldada dubleerivaid võtmeid. Seotud indeksi abil väärtuste tõhusaks leidmiseks saame teisendada asjakohase indeksiga pandade seeria või andmeraami sõnastikuobjektiks, millel on võtme-väärtuse paarid 'indeks: väärtus'. Selle ülesande täitmiseks saab kasutada meetodit 'to_dict()'. See funktsioon on sisseehitatud funktsioon, mis asub pandamooduli seeriaklassis. Andmeraam teisendatakse pythoni loendi sarnaseks andmesõnastikuks, kasutades meetodit pandas.to_dict(), olenevalt orient parameetri määratud väärtusest.
Kuidas teisendada pandad Pythoni sõnaraamatuks?
Pandade sõnaraamatuks teisendamiseks on mitu meetodit. Pandase andmeraami muutmiseks Pythoni sõnastikuks kasutame Pandas meetodit to_dict(). Funktsiooni to_dict() abil saame tagastatud sõnastiku võtme-väärtuse paare suunata mitmel viisil. Funktsiooni süntaks on järgmine:
Süntaks
pandas.to_dict ( ida = 'dikt', sisse = )
Parameetrid
orienteeruda: Millise andmetüübi veerud (seeriad) teisendada, määrab stringi väärtus ('dict', 'list', 'records', 'index', 'series', 'split'). Näiteks märksõna 'loend' annaks väljundina pythoni sõnastiku loendiobjektidest, mille väljundiks on klahvid 'Veeru nimi' ja 'Loend' (teisendatud seeria).
sisse: klass, saab läbida eksemplari või tegeliku klassina. Näiteks saab klassi eksemplari edasi anda vaikedikti korral. Parameetri vaikeväärtus on diktaat.
Tagastamise tüüp: Andmeraamist või seeriast teisendatud sõnastik.
Näide # 01: Pandade andmeraami teisendamine sõnastikuks
Kasutades funktsiooni pd.DataFrame() loendeid, loome mõne veeru ja ridadega põhiandmeraami, et saaksime selle hiljem pythoni sõnaraamatuks teisendada.
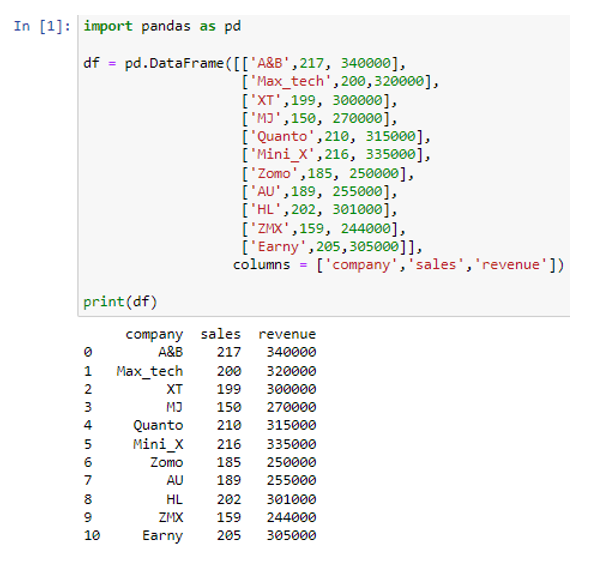
Oleme loonud oma andmeraami, edastades loendi funktsiooni pd.DataFrame() sees. Ülaltoodud andmeraamis on kolm veergu 'ettevõte', 'müük' ja 'tulu'. Veerus ettevõte oleme salvestanud juhuslike ettevõtete nimed (“A&B”, “Max_tech”, “XT”, “MJ”, “Quanto”, “Mini_X”, “Zomo”, “AU”, “HL” , 'ZMX', 'Earny'), veerg 'müük' esindab iga ettevõtte müüki kujul ('217', '200', '199', '150', '210', '216', '185' ”, '189', '202', '159', '205' ja veerg 'tulu' salvestab väärtused, mis kajastavad iga ettevõtte tulu ja vastavat müüki (340000 320000 300000 270000 315000 0 500 040 335 000 500 325000 305 000). Nüüd teisendame oma andmeraami 'df' Pythoni sõnaraamatuks.
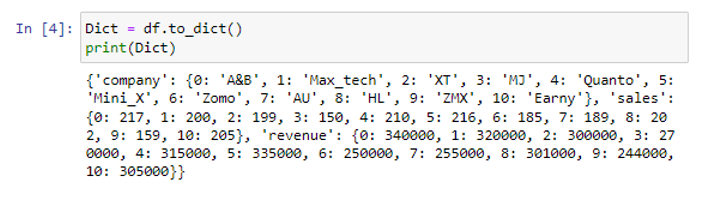
Rakendades df-andmeraamile meetodit to_dict(), oleme teisendanud pandade andmeraami sõnastikuks.
Näide # 02: CSV-failist loodud Pandase andmeraami teisendamine sõnaraamatuks
Näites nr 1 lõime andmeraami, kasutades loendis olevaid kortereid. Nüüd loome CSV-faili abil andmeraami ja teisendame selle funktsiooni to_dict() abil sõnaraamatuks.
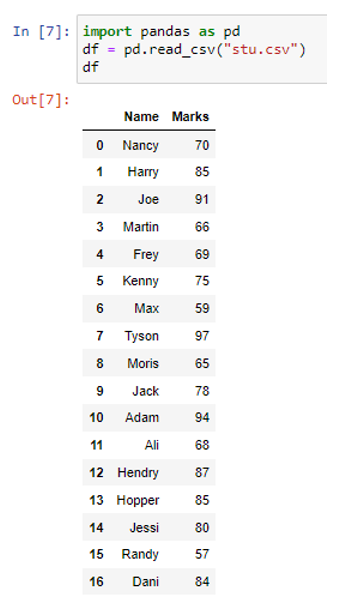
Faili lugemiseks andmeraamina oleme kasutanud funktsiooni pd.read_csv(). Ülaltoodud andmeraamis on kaks veergu (nimi ja märgid) ja seitseteist rida (0 kuni 16). Nüüd kasutame meetodit to_dict().
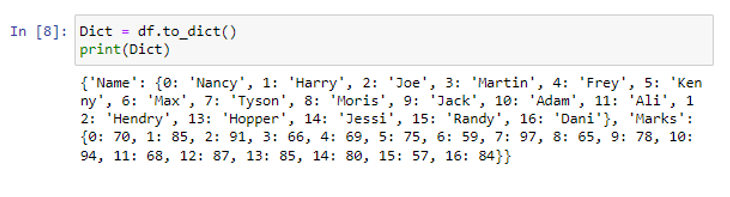
Funktsioon on teisendanud meie andmeraami 'df' Pythoni sõnaraamatuks.
Näide # 03: teisendage Pandade andmeraam väärtuste loendeid sisaldavaks sõnastikuks
Varasemates näidetes oleme pandad teisendanud püütoni sõnaraamatuks, mis sisaldab mitut sõnaraamatut. Andmeraami teisendamisel sõnastikuobjektiks peaksid veerusildid toimima sõnastiku võtmetena ja kõik veergude andmed või väärtused tuleks lisada saadud sõnastikku iga võtme väärtuste loendina.
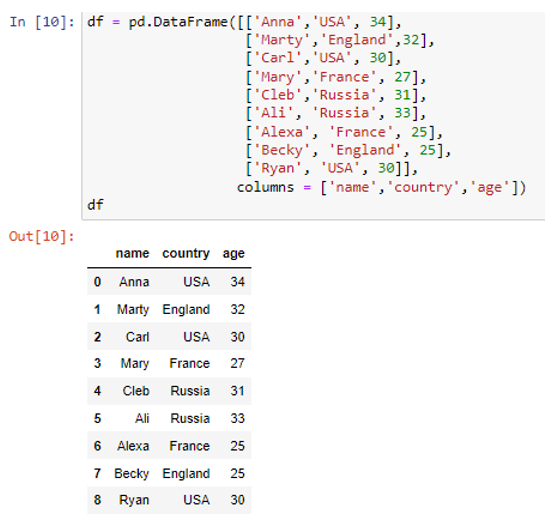
Oleme loonud andmeraami kolme veeruga “nimi”, “riik” ja “vanus”. Veergu 'nimi' oleme salvestanud andmeväärtused ('Anna', 'Marty', 'Carl', 'Mary', 'Cleb', 'Ali', 'Alexa', 'Becky', 'Ryan') . Kui teised veerud riik ja vanus on tugevad väärtused ('USA', 'Inglismaa', 'USA', 'Prantsusmaa', 'Venemaa', 'Venemaa', 'Prantsusmaa', 'Inglismaa', 'USA') ja ( vastavalt 34, 32, 30, 27, 31, 33, 35, 25, 30). Loome loendeid sisaldava sõnastiku, kasutades meetodi to_dict() parameetrit 'list'.
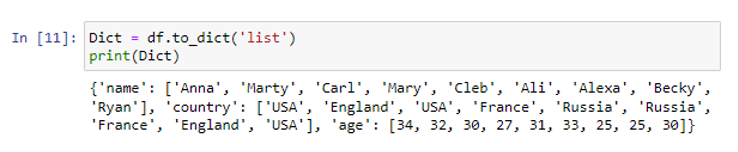
Kasutades loendi parameetrit argumendina funktsiooni to_list() sees, oleme loonud mitut loendit sisaldava sõnastiku.
Näide # 03: Panda andmeraami teisendamine väärtuste seeriat sisaldavaks sõnastikuks
Kui DataFrame on vaja sõnaraamatuks teisendada, toimib veeru nimi sõnastiku võtmetena ning rea indeks ja veerus olevad andmed sõnastiku vastavate võtmete väärtusena.
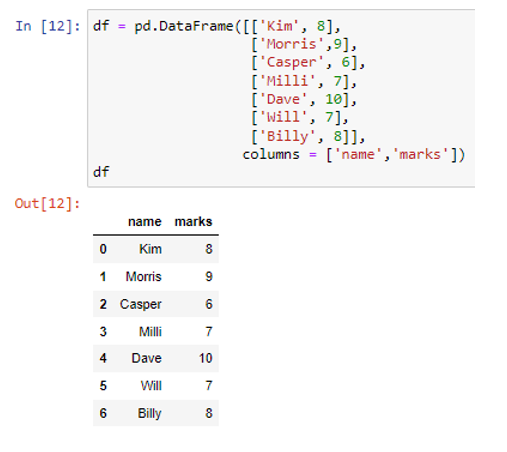
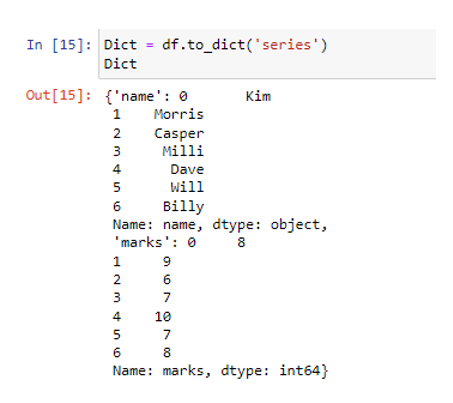
Oleme loonud vajaliku andmeraami kasutades pd.DataFrame() meetodit. Hiljuti loodud andmeraamis on meil kaks veergu. Nimeveerg salvestab andmeväärtused stringina ('Kim', 'Morris', 'Casper', 'Milli', 'Dave', 'Will', 'Billy'), samas kui märkide veerud koosnevad numbrilistest andmetest nagu ( 8, 9, 6, 7, 10, 7, 8). Funktsiooni to_dict() sees kasutame stringina parameetrit 'series'.
Näide # 04: Pandade andmeraami teisendamine ilma indeksi ja päiseta sõnastikuks
Funktsiooni to_dict() parameetrit 'split' saab kasutada andmete eraldamiseks DataFrame'ist ilma veergude päisteta või siis, kui peame eemaldama andmetest päise ja reaindeksi. Veerusildid, reaindeks ja tegelikud andmed jagatakse selle parameetri abil kolmeks komponendiks. Loome andmeraami, et saaksime selle sõnaraamatusse teisendamise ajal jagada kolmeks osaks.
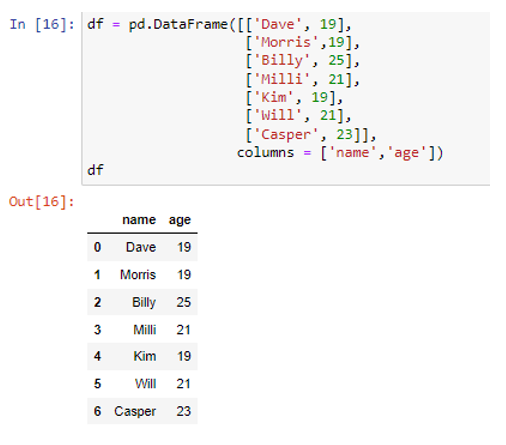
Oleme loonud kaks veergu siltidega 'nimi' ja 'vanus', mis sisaldavad väärtusi ('Dave', 'Morris', 'Billy', 'Milli', 'Kim', 'Will', 'Casper') ja (19, 19). , 25, 21, 19, 21, 23). Teisendame need Pythoni sõnaraamatuteks.

Võtme 'andmed' abil saame saadud sõnastikust andmed hankida ilma indeksi või päiseta.

Näide # 05: Pandade andmeraami teisendamine sõnastikuks rea ja reaindeksi järgi
Parameetrit 'rekord' saab kasutada funktsiooni to_dict() sees, et salvestada iga andmekaadri rea andmeid loendis mitmesse erinevasse sõnastikuobjekti või kui on vaja reapõhiseid andmeid. Tagatakse loend, mis sisaldab sõnastiku objekte. Sõnastik, mille võtmeks on veeru silt ja iga rea väärtuseks veeruandmed.
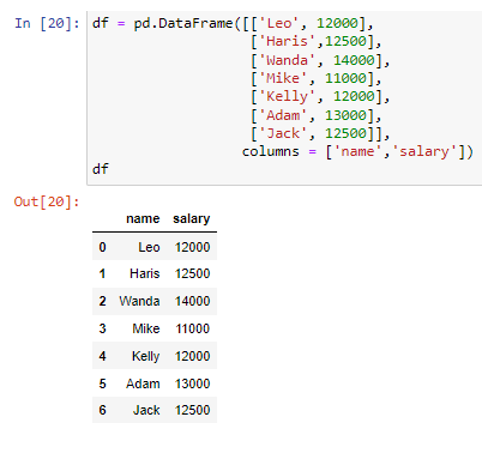
Oleme loonud andmeraami veergudega “nimi” ja “palk”. Veerg 'nimi' sisaldab andmeväärtusi ('Leo', 'Haris', 'Wanda', 'Mike', 'Kelly', 'Adam', 'Jack') ja palga veerg salvestab väärtused (12000, 12500). , 14000, 11000, 12000, 13000, 12500). Nüüd loome loendi mitme Pythoni sõnastikuga, mis sisaldavad iga rea andmeid.

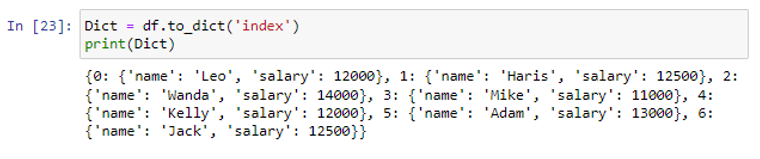
Indeksi parameetrit saab kasutada ka iga rea andmete teisendamiseks andmeraamist sõnastikku. Tagatakse loend, mis sisaldab sõnastiku üksusi. Iga rida loob sõnastiku. Kui rea indeks on võti ja väärtus on andmete sõnastik ja veeru silt.
Järeldus
Selles õpetuses oleme arutanud, kuidas saaksime andmeraami või pandaobjektid pythoni sõnaraamatuks teisendada. Oleme näinud funktsiooni to_dict() süntaksit, et mõista selle funktsiooni parameetreid ja seda, kuidas saate muuta funktsiooni väljundit, määrates funktsiooni erinevate parameetritega. Selle õpetuse näidetes oleme pandade objektide muutmiseks Pythoni sõnaraamatusse kasutanud meetodit to_dict(), mis on sisseehitatud pandafunktsioon.